Implementing Search for a Pure Frontend Application
As I have discussed before I recently built a video streaming website which has no backend and uses a static JSON object as its datastore. I wanted to add search to this website as it contains thousands of videos and finding the right video without searching would be cumbersome. Considering how the site has no backend there is no way to plug into a search engine so I would have to build one myself.
A simple implementation would perhaps be to iterate through all the videos and check if the titles contained the search query. However this screamed inefficiency to me and is reminiscent of running a WHERE LIKE '%text%' on an SQL server. So I considered how search engines tend to work and settled on the idea that what we needed was a search index.
The concept is quite simple: we go through all the videos and extract out every word in the titles, putting them in a list where each word had the IDs of the videos where they appeared:
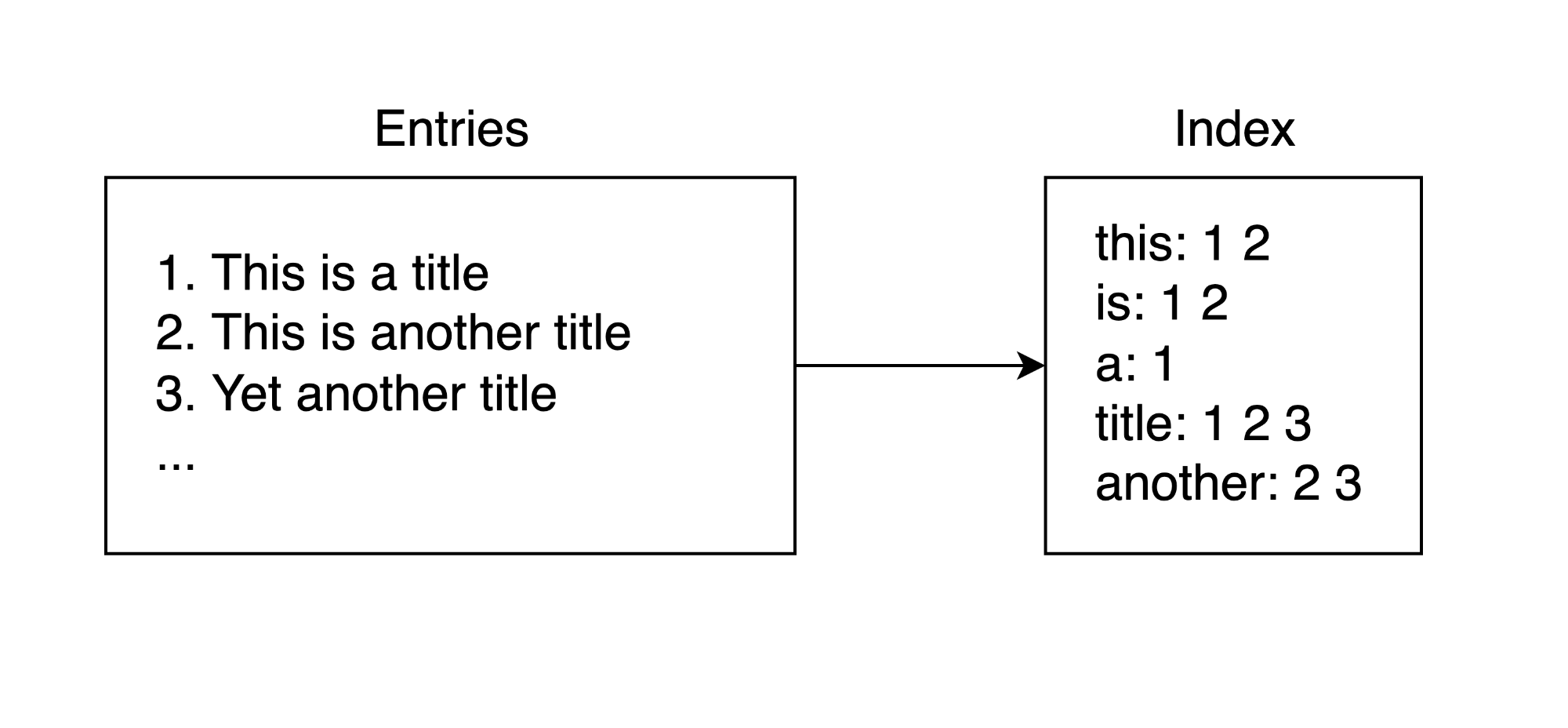
Now instead of comparing the search query against the titles themselves, we would check it against this word list. It also allowed us to preemptively format all the text in the titles, converting them to lowercase and removing any superfluous characters we may not want. We also did that to the search query itself, splitting it into separate words and formatting them so that we would be comparing similarly formatted text.
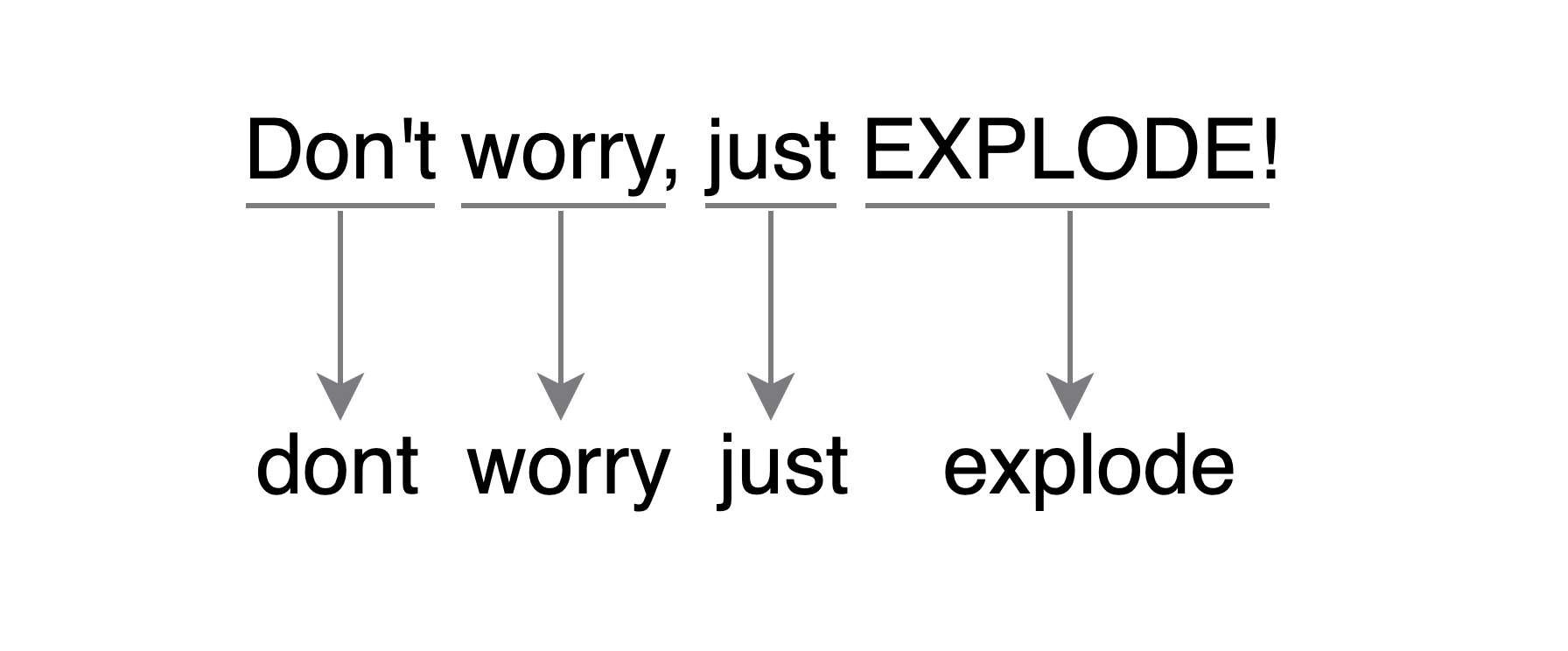
The search engine still had to iterate through each word, but the list of words was smaller than the list of videos and we didn't have to format the text in the title every time we compared. The resulting algorithm was quite small:
const searchWords = splitAndFormat(searchQuery)
const videos = new Set()
for (const searchWord of searchWords) {
for (const word of videoIndex) {
if (word.search(searchWord) !== 1) {
videoIndex[word].forEach(videoId => videos.add(videoId))
}
}
}
This was the first version of the search and it actually worked quite well! Pre-calculating the index didn't take enough time to be noticeable and the search was fast enough that I doubt a dedicated backend could've improved the query time. However, there was one issue that I noticed immediately, which was that the search results were returning in a seemingly random order.
They weren't actually random, but the search wasn't taking into consideration exact matches or whether it was matching on multiple words in a title. For example searching for "horror game" would return "This game is bad" and "Horrorific Feels" before "Best horror game", which is a better match. To alleviate this we would have to add scoring to the search results.
The algorithm was changed so that it would keep a track of which video was found and it's "match score". The score would be incremented by 10 if the word matched exactly and 5 if it didn't, checking each word in the search query individually:
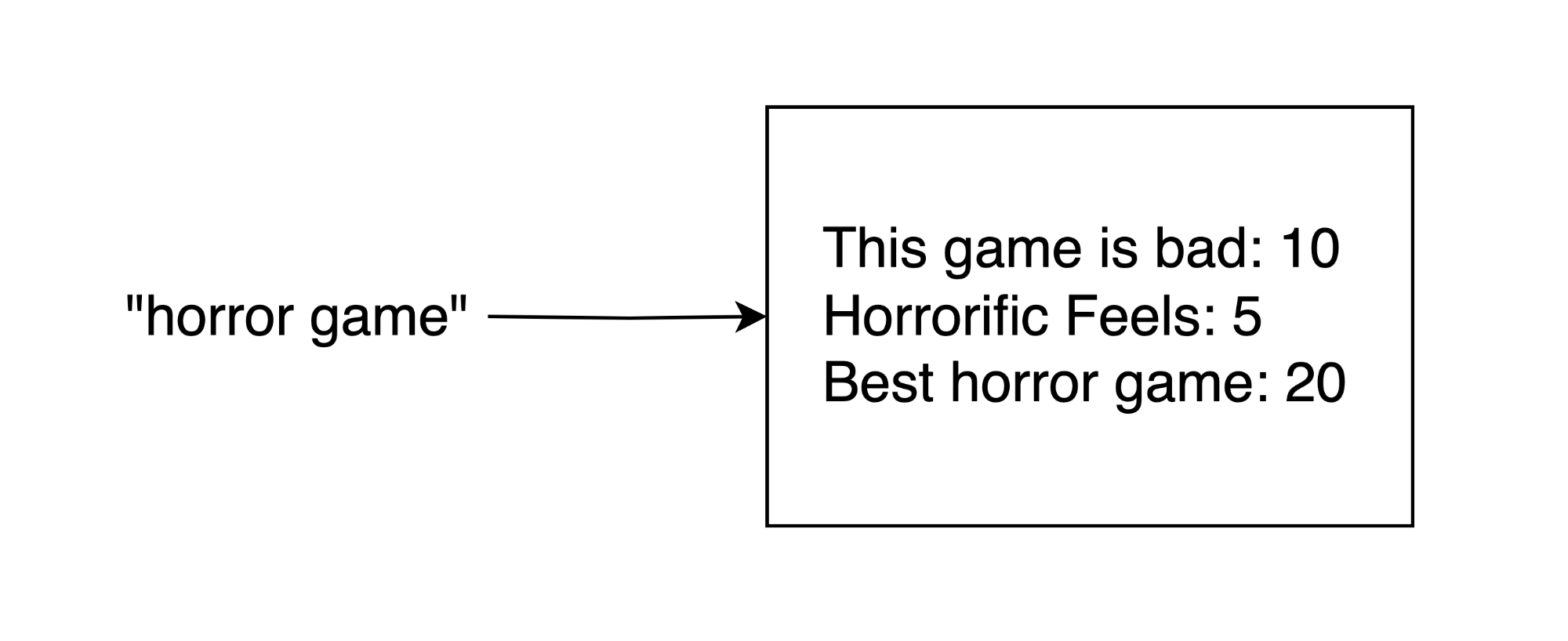
This worked out exactly as I'd hoped and that is where the search algorithm is at the moment. It is somewhat less naïve than just checking all the titles one after another, but there's probably lots of room for improvement. If you are so inclined, the project is available on GitHub so don't be afraid to check it out and provide any feedback/suggestions you may have.