Using JSON as a Data Store for a TypeScript Application
Let's start with some context: Giant Bomb is a website about video games. It was created in 2008 (15 years ago as of this writing) by Jeff Gerstmann and Ryan Davis as a response to Gerstmann's tactless firing from GameSpot, another website about video games. It has had a tumultuous life, having switched corporate owners many times, and last year the new owners decided to make the most ironic of moves by firing Gerstmann from the website he founded. This decision had the effect of radicalising a bunch of long-time fans into extracting all the video content and uploading it to a collection on Internet Archive. The legality of this questionable, but media conglomerates are notorious for shutting down websites without warning and we'd rather skirt the law than have the content disappear off the Internet.
However, the collection isn't particularly nice to browse if you're looking for a specific video or show, so I thought I'd volunteer my skills to alleviate the issue. Enter Duders Zone, a website whose design is inspired by 2010s-era Giant Bomb, and which features the videos collected into shows and with some features that (hopefully) provide a smoother browsing experience. It's built in TypeScript on Svelte and the source is available on GitHub.
The requirements for a site like this are a bit unique as the content is, in theory, completely static but the site has a few dynamic elements which make it impossible to use a pure Static Site Generator to create it. The random page (which shows a random video) and the historic page (which shows videos for the current day/month) need to be able to fetch videos independently from their shows. It also has a lot of videos organised into dozens of shows, so it would need some sort of data store to contain them with the means to fetch specific videos, sort by date, etc.
I considered using a formal database, but I wanted the project to have the least amount of maintenance as possible. As the videos themselves are hosted on Internet Archive the site just contains the meta data and some images, which could easily be hosted for free on any static host. The last thing I wanted was to have to run some sort of database or backend, so it all needed to be self-contained. I went back and forth on what I wanted to do for a while, but in the end I recreated a relational database using JSON.
That makes it sound fancy, but in reality it's just two JSON files: one which contains the video meta-data:
[
{
"id": "0001-quick-look-gamecock-demos-legendary",
"title": "Quick Look: Gamecock Demos Legendary",
"description": "Gamecock shows us Legendary. We ask if we can hit record...",
"date": "2008-08-27T00:00:00Z",
"thumbnail": "https://archive.org/services/img/0001-quick-look-gamecock-demos-legendary"
},
{
"id": "0002-quick-look-a-quick-look-at-burnout-bikes",
"title": "Quick Look: A Quick Look At Burnout Bikes",
"description": "Jeff takes a quick tour through the new content available for Burnout Paradise.",
"date": "2008-09-18T00:00:00Z",
"thumbnail": "https://archive.org/services/img/0002-quick-look-a-quick-look-at-burnout-bikes"
},
...
]
And the other which contains the show meta-data, including a list of IDs for the videos in the show:
[
{
"id": "endurance-run",
"title": "Endurance Run",
"description": "Vinny and Jeff sit down and take a crack at the latest game in the Shin Megami Tensei series. Will they make it through the entire game?",
"poster": "2437462-persona 4.jpg",
"logo": null,
"videos": [
"endurance-run-persona-4-part-01",
"endurance-run-persona-4-part-02",
"endurance-run-persona-4-part-03",
...
]
},
...
]
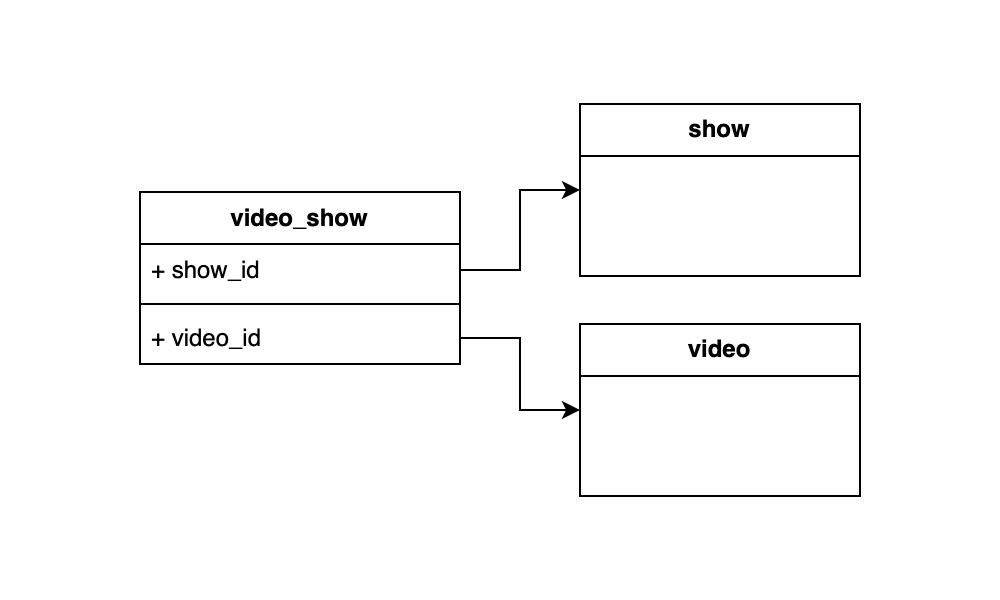
There are a myriad of other ways the data could've been modelled but in my head I was replicating the following structure:
Most (if not all) JavaScript frameworks have support for loading JSON directly from source files, so that's what I did:
import showData from '$lib/data/shows.json'
import videoData from '$lib/data/videos.json'
This resulted in generic objects and as I was using TypeScript I needed to define type interfaces for both the video and show:
interface Show {
readonly id: string
readonly title: string
readonly description: string
readonly logo?: string | null
readonly poster?: string
readonly videos: readonly string[]
}
interface Video {
readonly id: string
readonly title: string
readonly description: string
readonly date: Date
readonly show?: string
readonly thumbnail?: string
}
Then I iterated through the raw data coming from the JSON files and put them into maps of their respective types, with the key being the ID. The shows went in as-is, but for the videos I converted the date from a string to a proper Date object so that I could do some sorting and formatting:
const shows: { [key: string]: Show } = {}
for (const show of showData) {
shows[show.id] = show
}
const videos: { [key: string]: Video } = {}
for (const video of videoData) {
videos[video.id] = {
id: video.id,
title: video.title,
description: video.description,
date: new Date(video.date),
thumbnail: video.thumbnail,
}
}
Now I had a fully typed "database" of content which I could use to populate the pages, but I thought that for the sake of organisation I didn't want to just pass these around. So I ended up making a bunch of helper functions that could be used to "fetch" data:
function getRandomVideos(amount: number): Video[] {
const shuffled = Object.values(videos).sort(byRandom)
return shuffled.slice(0, amount)
}
function getShowById(id: string): Show | null {
return id in shows ? shows[id] : null
}
It's a basic concept but I'm quite happy with the results. The full data store takes up a few megabytes, which is in no way too much for the web browser to handle. It's also very simple to work with and requires no extra maintenance beyond what the SPA already needs. If you're interested in more details you can always check out the full source code, or you can watch a bunch of grown men get angry at a video game.